The Challenge: Lean Real-Time Initialization
At Palaimon, our autoStreams platform triggers immediate actions from real-time data. However, “real-time” often requires historical context—comparing live metrics to baselines from days or weeks ago.
To maintain operational agility, we follow a strict philosophy: The live system should be as lean as possible. We avoid long-running processes with massive state. Instead, we offload historical data to a dedicated backend that must provide:
- Cost-efficiency: Reliable storage for massive datasets.
- Fast cold-starts: Rapid retrieval of targeted subsets to initialize online systems.
- Simplicity: Low operational overhead, trading complex server-side queries for architectural ease.
The Architectural Shift: Serverless DataFrames
Traditional OLAP engines like TimescaleDB (Postgres-based) and ClickHouse (columnar) are the industry standards for high-performance time-series. They excel at complex SQL and massive aggregations but require “always-on” infrastructure.
ArcticDB offers a serverless alternative. Developed by Man Group, it is a high-performance, versioned DataFrame database that stores data directly in S3 or local storage. The “engine” is a Python library running within your application, reading directly from storage and eliminating the database server entirely.
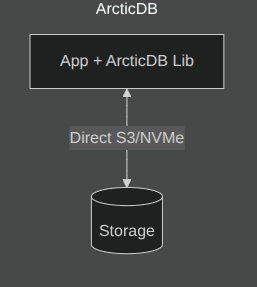
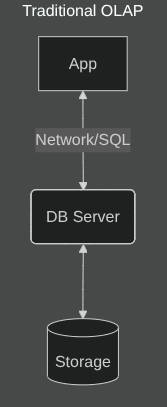
Technical Comparison
While TimescaleDB and ClickHouse offer full SQL support and materialized views, they come with “hidden” costs: 24/7 managed instances, sharding complexity, and hardware optimized for queries we rarely run.
Architecture & Features
| Aspect / Operation | ArcticDB | TimescaleDB | ClickHouse |
|---|---|---|---|
| Type | Library (client-side) | PostgreSQL extension | Column-store DB |
| Server Required | ❌ No | ✅ Yes | ✅ Yes |
| Storage | S3 / Local files | PostgreSQL storage | Local/remote disks |
| Scaling | Horizontal (via storage) | Vertical + sharding | Horizontal |
| Joins | Client-side only | ✅ Full SQL | ✅ Global |
| SQL Support | Python API only | ✅ Native | ✅ Native |
| Range Queries | ✅ Efficient | ✅ Optimized | ✅ Very fast |
| Predicate Pushdown | ✅ Yes | ✅ Yes | ✅ Yes |
| Aggregations | Basic | Full SQL | Very fast |
| Materialized Views | ❌ No | ✅ Yes | ✅ Yes |
The Trade-off: We sacrifice server-side joins for simplicity. Since we process data in-memory with Pandas, ArcticDB’s efficient range queries and built-in Time-Travel (versioning) provide exactly what we need without the “compute tax” of idle servers.
The Economics of Scale: 10 TB Benchmark
The difference between “server-backed” and “serverless” becomes business-defining at scale. Here is the estimated monthly cost for storing and accessing 10 TB of time-series data on AWS.
| Feature | TimescaleDB (Managed) | ClickHouse (Managed) | ArcticDB (S3 + Lambda/EC2) |
|---|---|---|---|
| Compute | ~$450 (High-mem) | ~$600 (Prod cluster) | $0 (In app runtime) |
| Storage | ~$1,000 (EBS/IOPS) | ~$1,000 (SSD) | ~$230 (S3 Standard) |
| Total/Mo | ~$1,450 | ~$1,600 | ~$230 |
Performance on Your Hardware
For on-prem or sovereign clouds, ArcticDB achieves retrieval speeds that networked databases cannot match. Zero-copy reads from local NVMe SSDs bypass network protocol overhead entirely.
| Component | Traditional Cluster | ArcticDB (On NVMe) |
|---|---|---|
| Drives | 3x 4TB SSDs (RAID) | 1x 10TB NVMe SSD |
| Admin | ~2-4 Days/Month | ~1 Hour/Month |
| Retrieval | Network limited (~1-10 Gbps) | Bus limited (~32-64 Gbps) |
Conclusion
For initializing real-time systems with historical windows, we don’t need a full database server—we need fast, targeted retrieval. ArcticDB’s library-based architecture delivers cheaper storage (S3), faster retrieval (direct NVMe), and zero maintenance.
Don’t pay for an idle server to watch your data grow. Go serverless.